Geo (development) (PREMIUM SELF)
Geo connects GitLab instances together. One GitLab instance is designated as a primary site and can be run with multiple secondary sites. Geo orchestrates quite a few components that can be seen on the diagram below and are described in more detail within this document.
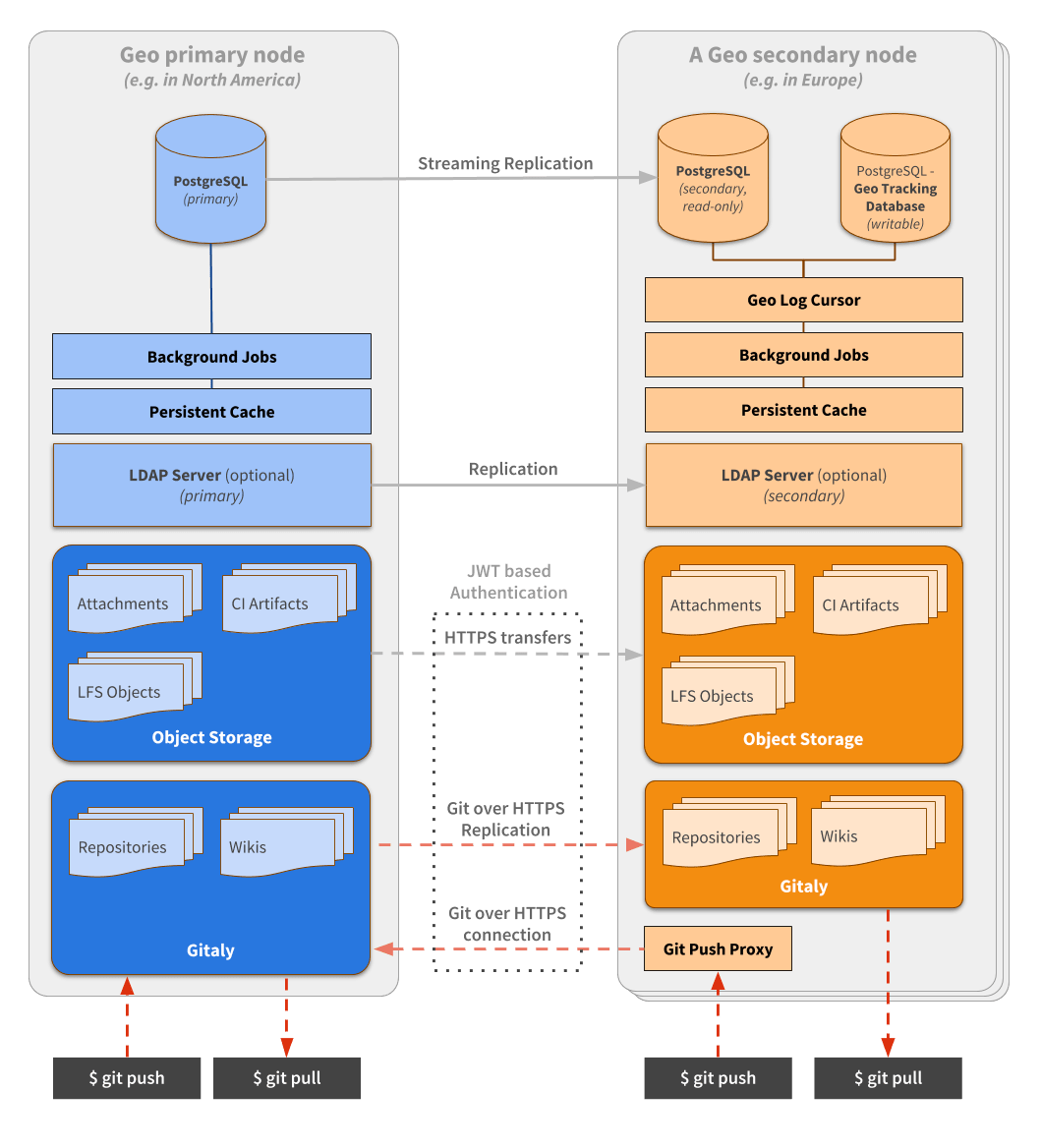
Replication layer
Geo handles replication for different components:
- Database: includes the entire application, except cache and jobs.
- Git repositories: includes both projects and wikis.
- Blobs: includes anything from images attached on issues to raw logs and assets from CI.
With the exception of the Database replication, on a secondary site, everything is coordinated by the Geo Log Cursor.
Replication states
The following diagram illustrates how the replication works. Some allowed transitions are omitted for clarity.
stateDiagram-v2
Pending --> Started
Started --> Synced
Started --> Failed
Synced --> Pending: Mark for resync
Failed --> Pending: Mark for resync
Failed --> Started: RetryGeo Log Cursor daemon
The Geo Log Cursor daemon is a separate process running on each secondary site. It monitors the Geo Event Log for new events and creates background jobs for each specific event type.
For example when a repository is updated, the Geo primary site creates
a Geo event with an associated repository updated event. The Geo Log Cursor daemon
picks the event up and schedules a Geo::ProjectSyncWorker job which
uses the Geo::RepositorySyncService and Geo::WikiSyncService classes
to update the repository and the wiki respectively.
The Geo Log Cursor daemon can operate in High Availability mode automatically. The daemon tries to acquire a lock from time to time and once acquired, it behaves as the active daemon.
Any additional running daemons on the same site, is in standby mode, ready to resume work if the active daemon releases its lock.
We use the ExclusiveLease lock type with a small TTL, that is renewed at every
pooling cycle. That allows us to implement this global lock with a timeout.
At the end of the pooling cycle, if the daemon can't renew and/or reacquire the lock, it switches to standby mode.
Database replication
Geo uses streaming replication to replicate the database from the primary to the secondary sites. This replication gives the secondary sites access to all the data saved in the database. So users can log in on the secondary and read all the issues, merge requests, and so on, on the secondary site.
Repository replication
Geo also replicates repositories. Each secondary site keeps track of the state of every repository in the tracking database.
There are a few ways a repository gets replicated by the:
Project Registry
The Geo::ProjectRegistry class defines the model used to track the
state of repository replication. For each project in the main
database, one record in the tracking database is kept.
It records the following about repositories:
- The last time they were synced.
- The last time they were successfully synced.
- If they need to be resynced.
- When a retry should be attempted.
- The number of retries.
- If and when they were verified.
It also stores these attributes for project wikis in dedicated columns.
Repository Sync worker
The Geo::RepositorySyncWorker class runs periodically in the
background and it searches the Geo::ProjectRegistry model for
projects that need updating. Those projects can be:
- Unsynced: Projects that have never been synced on the secondary site and so do not exist yet.
- Updated recently: Projects that have a
last_repository_updated_attimestamp that is more recent than thelast_repository_successful_sync_attimestamp in theGeo::ProjectRegistrymodel. - Manual: The administrator can manually flag a repository to resync in the Geo Admin Area.
When we fail to fetch a repository on the secondary RETRIES_BEFORE_REDOWNLOAD
times, Geo does a so-called re-download. It will do a clean clone
into the @geo-temporary directory in the root of the storage. When
it's successful, we replace the main repository with the newly cloned one.
Blob replication
Blobs such as uploads, LFS objects, and CI job artifacts, are replicated to the secondary site with the Self-Service Framework. To track the state of syncing, each model has a corresponding registry table, for example Upload has Geo::UploadRegistry in the PostgreSQL Geo Tracking Database.
Blob replication happy path workflows between services
Job artifacts are used in the diagrams below, as one example of a blob.
Replicating a new job artifact
Primary site:
sequenceDiagram
participant R as Runner
participant P as Puma
participant DB as PostgreSQL
participant SsP as Secondary site PostgreSQL
R->>P: Upload artifact
P->>DB: Insert `ci_job_artifacts` row
P->>DB: Insert `geo_events` row
P->>DB: Insert `geo_event_log` row
DB->>SsP: Replicate rows- A Runner uploads an artifact
-
Puma inserts
ci_job_artifactsrow - Puma inserts
geo_eventsrow with data like "Job Artifact with ID 123 was updated" - Puma inserts
geo_event_logrow pointing to thegeo_eventsrow (because we built SSF on top of some legacy logic) - PostgreSQL streaming replication inserts the rows in the read replica
Secondary site, after the PostgreSQL DB rows have been replicated:
sequenceDiagram
participant DB as PostgreSQL
participant GLC as Geo Log Cursor
participant R as Redis
participant S as Sidekiq
participant TDB as PostgreSQL Tracking DB
participant PP as Primary site Puma
GLC->>DB: Query `geo_event_log`
GLC->>DB: Query `geo_events`
GLC->>R: Enqueue `Geo::EventWorker`
S->>R: Pick up `Geo::EventWorker`
S->>TDB: Insert to `job_artifact_registry`, "starting sync"
S->>PP: GET <primary site internal URL>/geo/retrieve/job_artifact/123
S->>TDB: Update `job_artifact_registry`, "synced"-
Geo Log Cursor loop finds the new
geo_event_logrow - Geo Log Cursor processes the
geo_eventsrow- Geo Log Cursor enqueues
Geo::EventWorkerjob passing through thegeo_eventsrow data
- Geo Log Cursor enqueues
-
Sidekiq picks up
Geo::EventWorkerjob- Sidekiq inserts
job_artifact_registryrow in the PostgreSQL Geo Tracking Database because it doesn't exist, and marks it "started sync" - Sidekiq does a GET request on an API endpoint at the primary Geo site and downloads the file
- Sidekiq marks the
job_artifact_registryrow as "synced" and "pending verification"
- Sidekiq inserts
Backfilling existing job artifacts
- Sysadmin has an existing GitLab site without Geo
- There are existing CI jobs and job artifacts
- Sysadmin sets up a new GitLab site and configures it to be a secondary Geo site
Secondary site:
There are two cronjobs running every minute: Geo::Secondary::RegistryConsistencyWorker and Geo::RegistrySyncWorker. The workflow below is split into two, along those lines.
sequenceDiagram
participant SC as Sidekiq-cron
participant R as Redis
participant S as Sidekiq
participant DB as PostgreSQL
participant TDB as PostgreSQL Tracking DB
SC->>R: Enqueue `Geo::Secondary::RegistryConsistencyWorker`
S->>R: Pick up `Geo::Secondary::RegistryConsistencyWorker`
S->>DB: Query `ci_job_artifacts`
S->>TDB: Query `job_artifact_registry`
S->>TDB: Insert to `job_artifact_registry`-
Sidekiq-cron enqueues a
Geo::Secondary::RegistryConsistencyWorkerjob every minute. As long as it is actively doing work (creating and deleting rows), this job immediately reenqueues itself. This job uses an exclusive lease to prevent multiple instances of itself from running simultaneously. -
Sidekiq picks up
Geo::Secondary::RegistryConsistencyWorkerjob- Sidekiq queries
ci_job_artifactstable for up to 10000 rows - Sidekiq queries
job_artifact_registrytable for up to 10000 rows - Sidekiq inserts a
job_artifact_registryrow in the PostgreSQL Geo Tracking Database corresponding to the existing Job Artifact
- Sidekiq queries
sequenceDiagram
participant SC as Sidekiq-cron
participant R as Redis
participant S as Sidekiq
participant DB as PostgreSQL
participant TDB as PostgreSQL Tracking DB
participant PP as Primary site Puma
SC->>R: Enqueue `Geo::RegistrySyncWorker`
S->>R: Pick up `Geo::RegistrySyncWorker`
S->>TDB: Query `*_registry` tables
S->>R: Enqueue `Geo::EventWorker`s
S->>R: Pick up `Geo::EventWorker`
S->>TDB: Insert to `job_artifact_registry`, "starting sync"
S->>PP: GET <primary site internal URL>/geo/retrieve/job_artifact/123
S->>TDB: Update `job_artifact_registry`, "synced"-
Sidekiq-cron enqueues a
Geo::RegistrySyncWorkerjob every minute. As long as it is actively doing work, this job loops for up to an hour scheduling sync jobs. This job uses an exclusive lease to prevent multiple instances of itself from running simultaneously. -
Sidekiq picks up
Geo::RegistrySyncWorkerjob- Sidekiq queries all
registrytables in the PostgreSQL Geo Tracking Database for "never attempted sync" rows. It interleaves rows from each table and adds them to an in-memory queue. - If the previous step yielded less than 1000 rows, then Sidekiq queries all
registrytables for "failed sync and ready to retry" rows and interleaves those and adds them to the in-memory queue. - Sidekiq enqueues
Geo::EventWorkerjobs with arguments like "Job Artifact with ID 123 was updated" for each item in the queue, and tracks the enqueued Sidekiq job IDs. - Sidekiq stops enqueuing
Geo::EventWorkerjobs when "maximum concurrency limit" settings are reached - Sidekiq loops doing this kind of work until it has no more to do
- Sidekiq queries all
- Sidekiq picks up
Geo::EventWorkerjob- Sidekiq marks the
job_artifact_registryrow as "started sync" - Sidekiq does a GET request on an API endpoint at the primary Geo site and downloads the file
- Sidekiq marks the
job_artifact_registryrow as "synced" and "pending verification"
- Sidekiq marks the
Verifying a new job artifact
Primary site:
sequenceDiagram
participant Ru as Runner
participant P as Puma
participant DB as PostgreSQL
participant SC as Sidekiq-cron
participant Rd as Redis
participant S as Sidekiq
participant F as Filesystem
Ru->>P: Upload artifact
P->>DB: Insert `ci_job_artifacts`
P->>DB: Insert `ci_job_artifact_states`
SC->>Rd: Enqueue `Geo::VerificationCronWorker`
S->>Rd: Pick up `Geo::VerificationCronWorker`
S->>DB: Query `ci_job_artifact_states`
S->>Rd: Enqueue `Geo::VerificationBatchWorker`
S->>Rd: Pick up `Geo::VerificationBatchWorker`
S->>DB: Query `ci_job_artifact_states`
S->>DB: Update `ci_job_artifact_states` row, "started"
S->>F: Checksum file
S->>DB: Update `ci_job_artifact_states` row, "succeeded"- A Runner uploads an artifact
-
Puma creates a
ci_job_artifactsrow - Puma creates a
ci_job_artifact_statesrow to store verification state.- The row is marked "pending verification"
-
Sidekiq-cron enqueues a
Geo::VerificationCronWorkerjob every minute -
Sidekiq picks up the
Geo::VerificationCronWorkerjob- Sidekiq queries
ci_job_artifact_statesfor the number of rows marked "pending verification" or "failed verification and ready to retry" - Sidekiq enqueues one or more
Geo::VerificationBatchWorkerjobs, limited by the "maximum verification concurrency" setting
- Sidekiq queries
- Sidekiq picks up
Geo::VerificationBatchWorkerjob- Sidekiq queries
ci_job_artifact_statesfor rows marked "pending verification" - If the previous step yielded less than 10 rows, then Sidekiq queries
ci_job_artifact_statesfor rows marked "failed verification and ready to retry" - For each row
- Sidekiq marks it "started verification"
- Sidekiq gets the SHA256 checksum of the file
- Sidekiq saves the checksum in the row and marks it "succeeded verification"
- Now secondary Geo sites can compare against this checksum
- Sidekiq queries
Secondary site:
sequenceDiagram
participant SC as Sidekiq-cron
participant R as Redis
participant S as Sidekiq
participant TDB as PostgreSQL Tracking DB
participant F as Filesystem
participant DB as PostgreSQL
SC->>R: Enqueue `Geo::VerificationCronWorker`
S->>R: Pick up `Geo::VerificationCronWorker`
S->>TDB: Query `job_artifact_registry`
S->>R: Enqueue `Geo::VerificationBatchWorker`
S->>R: Pick up `Geo::VerificationBatchWorker`
S->>TDB: Query `job_artifact_registry`
S->>TDB: Update `job_artifact_registry` row, "started"
S->>F: Checksum file
S->>DB: Query `ci_job_artifact_states`
S->>TDB: Update `job_artifact_registry` row, "succeeded"- After the artifact is successfully synced, it becomes "pending verification"
-
Sidekiq-cron enqueues a
Geo::VerificationCronWorkerjob every minute -
Sidekiq picks up the
Geo::VerificationCronWorkerjob- Sidekiq queries
job_artifact_registryin the PostgreSQL Geo Tracking Database for the number of rows marked "pending verification" or "failed verification and ready to retry" - Sidekiq enqueues one or more
Geo::VerificationBatchWorkerjobs, limited by the "maximum verification concurrency" setting
- Sidekiq queries
- Sidekiq picks up
Geo::VerificationBatchWorkerjob- Sidekiq queries
job_artifact_registryin the PostgreSQL Geo Tracking Databasef for rows marked "pending verification" - If the previous step yielded less than 10 rows, then Sidekiq queries
job_artifact_registryfor rows marked "failed verification and ready to retry" - For each row
- Sidekiq marks it "started verification"
- Sidekiq gets the SHA256 checksum of the file
- Sidekiq saves the checksum in the row
- Sidekiq compares the checksum against the checksum in the
ci_job_artifact_statesrow which was replicated by PostgreSQL - If the checksum matches, then Sidekiq marks the
job_artifact_registryrow "succeeded verification"
- Sidekiq queries
Authentication
To authenticate file transfers, each GeoNode record has two fields:
- A public access key (
access_keyfield). - A secret access key (
secret_access_keyfield).
The secondary site authenticates itself via a JWT request.
When the secondary site wishes to download a file, it sends an
HTTP request with the Authorization header:
Authorization: GL-Geo <access_key>:<JWT payload>The primary site uses the access_key field to look up the
corresponding secondary site and decrypts the JWT payload,
which contains additional information to identify the file
request. This ensures that the secondary site downloads the right
file for the right database ID. For example, for an LFS object, the
request must also include the SHA256 sum of the file. An example JWT
payload looks like:
{"data": {sha256: "31806bb23580caab78040f8c45d329f5016b0115"}, iat: "1234567890"}If the requested file matches the requested SHA256 sum, then the Geo primary site sends data via the X-Sendfile feature, which allows NGINX to handle the file transfer without tying up Rails or Workhorse.
NOTE: JWT requires synchronized clocks between the machines involved, otherwise it may fail with an encryption error.
Git Push to Geo secondary
The Git Push Proxy exists as a functionality built inside the gitlab-shell component.
It is active on a secondary site only. It allows the user that has cloned a repository
from the secondary site to push to the same URL.
Git push requests directed to a secondary site will be sent over to the primary site,
while pull requests will continue to be served by the secondary site for maximum efficiency.
HTTPS and SSH requests are handled differently:
- With HTTPS, we will give the user a
HTTP 302 Redirectpointing to the project on the primary site. The Git client is wise enough to understand that status code and process the redirection. - With SSH, because there is no equivalent way to perform a redirect, we have to proxy the request.
This is done inside
gitlab-shell, by first translating the request to the HTTP protocol, and then proxying it to the primary site.
The gitlab-shell daemon knows when to proxy based on the response
from /api/v4/allowed. A special HTTP 300 status code is returned and we execute a "custom action",
specified in the response body. The response contains additional data that allows the proxied push operation
to happen on the primary site.
Using the Tracking Database
Along with the main database that is replicated, a Geo secondary site has its own separate Tracking database.
The tracking database contains the state of the secondary site.
Any database migration that needs to be run as part of an upgrade needs to be applied to the tracking database on each secondary site.
Configuration
The database configuration is set in config/database.yml.
The directory ee/db/geo
contains the schema and migrations for this database.
To write a migration for the database, run:
rails g migration [args] [options] --database geoGeo should continue using Gitlab::Database::Migration[1.0] until the gitlab_geo schema is supported, and is for the time being exempt from being validated by Gitlab::Database::Migration[2.0]. This requires a developer to manually amend the migration file to change from [2.0] to [1.0] due to the migration defaults being 2.0.
For more information, see the Enable Geo migrations to use Migration[2.0] issue.
To migrate the tracking database, run:
bundle exec rake db:migrate:geoFinders
Geo uses Finders, which are classes take care of the heavy lifting of looking up projects/attachments/ and so on, in the tracking database and main database.
Redis
Redis on the secondary site works the same as on the primary site. It is used for caching, storing sessions, and other persistent data.
Redis data replication between primary and secondary site is not used, so sessions and so on, aren't shared between sites.
Object Storage
GitLab can optionally use Object Storage to store data it would otherwise store on disk. These things can be:
- LFS Objects
- CI Job Artifacts
- Uploads
Objects that are stored in object storage, are not handled by Geo. Geo ignores items in object storage. Either:
- The object storage layer should take care of its own geographical replication.
- All secondary sites should use the same storage site.
Verification
Verification states
The following diagram illustrates how the verification works. Some allowed transitions are omitted for clarity.
stateDiagram-v2
Pending --> Started
Pending --> Disabled: No primary checksum
Disabled --> Started: Primary checksum succeeded
Started --> Succeeded
Started --> Failed
Succeeded --> Pending: Mark for reverify
Failed --> Pending: Mark for reverify
Failed --> Started: RetryRepository verification
Repositories are verified with a checksum.
The primary site calculates a checksum on the repository. It
basically hashes all Git refs together and stores that hash in the
project_repository_states table of the database.
The secondary site does the same to calculate the hash of its clone, and compares the hash with the value the primary site calculated. If there is a mismatch, Geo will mark this as a mismatch and the administrator can see this in the Geo Admin Area.
Geo proxying
Geo secondaries can proxy web requests to the primary. Read more on the Geo proxying (development) page.
Glossary
Primary site
A primary site is the single site in a Geo setup that read-write capabilities. It's the single source of truth and the Geo secondary sites replicate their data from there.
In a Geo setup, there can only be one primary site. All secondary sites connect to that primary.
Secondary site
A secondary site is a read-only replica of the primary site running in a different geographical location.
Streaming replication
Geo depends on the streaming replication feature of PostgreSQL. It completely replicates the database data and the database schema. The database replica is a read-only copy.
Streaming replication depends on the Write Ahead Logs, or WAL. Those logs are copied over to the replica and replayed there.
Since streaming replication also replicates the schema, the database migration do not need to run on the secondary sites.
Tracking database
A database on each Geo secondary site that keeps state for the site on which it resides. Read more in Using the Tracking database.
Geo Event Log
The Geo primary stores events in the geo_event_log table. Each
entry in the log contains a specific type of event. These type of
events include:
- Repository Deleted event
- Repository Renamed event
- Repositories Changed event
- Repository Created event
- Hashed Storage Migrated event
- LFS Object Deleted event
- Hashed Storage Attachments event
- Job Artifact Deleted event
- Upload Deleted event
Code features
Gitlab::Geo utilities
Small utility methods related to Geo go into the
ee/lib/gitlab/geo.rb
file.
Many of these methods are cached using the RequestStore class, to
reduce the performance impact of using the methods throughout the
codebase.
Current site
The class method .current_node returns the GeoNode record for the
current site.
We use the host, port, and relative_url_root values from
gitlab.yml and search in the database to identify which site we are
in (see GeoNode.current_node).
Primary or secondary
To determine whether the current site is a primary site or a
secondary site use the .primary? and .secondary? class
methods.
It is possible for these methods to both return false on a site when
the site is not enabled. See Enablement.
Geo Database configured?
There is also an additional gotcha when dealing with things that
happen during initialization time. In a few places, we use the
Gitlab::Geo.geo_database_configured? method to check if the site has
the tracking database, which only exists on the secondary
site. This overcomes race conditions that could happen during
bootstrapping of a new site.
Enablement
We consider Geo feature enabled when the user has a valid license with the feature included, and they have at least one site defined at the Geo Nodes screen.
See Gitlab::Geo.enabled? and Gitlab::Geo.license_allows? methods.
Read-only
All Geo secondary sites are read-only.
The general principle of a read-only database
applies to all Geo secondary sites. So the
Gitlab::Database.read_only? method will always return true on a
secondary site.
When some write actions are not allowed because the site is a
secondary, consider adding the Gitlab::Database.read_only? or
Gitlab::Database.read_write? guard, instead of Gitlab::Geo.secondary?.
The database itself will already be read-only in a replicated setup, so we don't need to take any extra step for that.
Steps needed to replicate a new data type
As GitLab evolves, we constantly need to add new resources to the Geo replication system. The implementation depends on resource specifics, but there are several things that need to be taken care of:
- Event generation on the primary site. Whenever a new resource is changed/updated, we need to create a task for the Log Cursor.
- Event handling. The Log Cursor needs to have a handler for every event type generated by the primary site.
- Dispatch worker (cron job). Make sure the backfill condition works well.
- Sync worker.
- Registry with all possible states.
- Verification.
- Cleaner. When sync settings are changed for the secondary site, some resources need to be cleaned up.
- Geo Node Status. We need to provide API endpoints as well as some presentation in the GitLab Admin Area.
- Health Check. If we can perform some pre-cheсks and make site unhealthy if something is wrong, we should do that.
The
rake gitlab:geo:checkcommand has to be updated too.
History of communication channel
The communication channel has changed since first iteration, you can check here historic decisions and why we moved to new implementations.
Custom code (GitLab 8.6 and earlier)
In GitLab versions before 8.6, custom code is used to handle notification from primary site to secondary sites by HTTP requests.
System hooks (GitLab 8.7 to 9.5)
Later, it was decided to move away from custom code and begin using system hooks. More people were using them, so many would benefit from improvements made to this communication layer.
There is a specific internal endpoint in our API code (Grape),
that receives all requests from this System Hooks:
/api/v4/geo/receive_events.
We switch and filter from each event by the event_name field.
Geo Log Cursor (GitLab 10.0 and up)
In GitLab 10.0 and later, System Webhooks are no longer
used and Geo Log Cursor is used instead. The Log Cursor traverses the
Geo::EventLog rows to see if there are changes since the last time
the log was checked and will handle repository updates, deletes,
changes, and renames.
The table is within the replicated database. This has two advantages over the old method:
- Replication is synchronous and we preserve the order of events.
- Replication of the events happen at the same time as the changes in the database.
Self-service framework
If you want to add easy Geo replication of a resource you're working on, check out our self-service framework.
Geo development workflow
GET:Geo pipeline
As part of the package-and-qa pipeline, there is an option to manually trigger a job named GET:Geo. This
pipeline uses GET to spin up a
1k Geo installation,
and run the gitlab-qa Geo scenario against the instance.
When working on Geo features, it is a good idea to ensure the qa-geo job passes in a triggered GET:Geo pipeline.
The pipelines that control the provisioning and teardown of the instance are included in The GitLab Environment Toolkit Configs Geo subproject.
When adding new functionality, consider adding new tests to verify the behavior. For steps, see the QA documentation.
Architecture
The pipeline involves the interaction of multiple different projects:
- GitLab - The package-and-qa job is launched from merge requests in this project.
-
omnibus-gitlab- Builds relevant artifacts containing the changes from the triggering merge request pipeline. - GET-Configs/Geo - Coordinates the lifecycle of a short-lived Geo installation that can be evaluated.
-
GET - Contains the necessary logic for creating and destroying Geo installations. Used by
GET-Configs/Geo. -
gitlab-qa- Tool for running automated tests against a GitLab instance.
flowchart TD;
GET:Geo-->getcg
Provision-->Terraform
Configure-->Ansible
Geo-->Ansible
QA-->gagq
subgraph "omnibus-gitlab-mirror"
GET:Geo
end
subgraph getcg [GitLab-environment-toolkit-configs/Geo]
direction LR
Generate-terraform-config-->Provision
Provision-->Generate-ansible-config
Generate-ansible-config-->Configure
Configure-->Geo
Geo-->QA
QA-->Destroy-geo
end
subgraph get [GitLab Environment Toolkit]
Terraform
Ansible
end
subgraph GitLab QA
gagq[GitLab QA Geo Scenario]
end